David Furnes is a software engineer based in Brooklyn, New York. 🥞
The Dynamo Paper
The ideas behind DynamoDB, Amazon's serverless key-value database.
DynamoDB is Amazon's key-value/document database service. It's a fully "serverless" database with pay-per-request pricing & nearly effortless scaling. It's also completely closed-source, so unlike MongoDB or SQLite, it's hard to know what's really happening behind the scenes.
I've been using DynamoDB a lot recently at work, and I was curious to learn more about its internals. Luckily, the team behind Dynamo, Amazon's in-house database & the predecessor of DynamoDB, published an academic paper on just that!
While technically not the same database we all use today, Dynamo gives some great insights into where DynamoDB came from & why it works the way it does. (For example, did you know it might use MySQL behind the scenes? I didn't!)
A Purpose-Built Database
The "NoSQL" movement came out of the realization that not every application interacts with its data in the same way. Relational databases, like MySQL, make a lot of trade-offs to maintain their flexibility and strict data integrity.
Amazon looked at how they used their database, though, and found that 70% of operations simply requested a single record by primary key, and another 20% asked for a set of rows from within a single table. So 90% of queries didn't use JOIN or other tools in the relational database's toolkit!
With that in mind, Amazon engineers decided that they could sacrifice some of the consistency and isolation guarantees from ACID in order to make it easier to scale the database horizontally (by splitting it up into a bunch of servers, rather than making one server more and more powerful):
Experience at Amazon has shown that data stores that provide ACID guarantees tend to have poor availability. This has been widely acknowledged by both the industry and academia. Dynamo targets applications that operate with weaker consistency (the “C” in ACID) if this results in high availability. Dynamo does not provide any isolation guarantees and permits only single key updates. pg. 206
Rather than build a database completely from scratch, Dynamo was built on top of a lot of other existing databases like Berkeley DB and even MySQL! The big difference was how Dynamo arranged each underlying database.
Napster for Databases
Dynamo may have been built on top of existing databases, but it's design was really inspired by peer-to-peer file-sharing networks like Freenet and Gnutella.
Because files in these networks were spread across thousands of computers and these computers would go online & offline unpredictably, they had to establish their own links to each other & maintain their own maps to help route queries to the right place.
Dynamo can be characterized as a zero-hop DHT, where each node maintains enough routing information locally to route a request to the appropriate node directly. pg. 209
This was one of the keys to solving Amazon's horizontal scaling problem. Instead of one really powerful machine knowing where to find every record, each machine kept enough of a "map" to route requests directly to their final destination. This allowed the entire database to run on cheap commodity hardware & scale near infinitely.
Maintaining this map wasn't necessarily simple, though. Like in file-sharing networks, machines could go offline unpredictably due to network issues. Engineers might also purposefully add new machines to "scale up" a database, and then those maps would have to be updated efficiently.
Consistent Hashing
Hash tables, or "dictionaries", are a way of storing data & quickly looking it up by a unique key. They generally work by splitting data into a bunch of arrays, and using a hash function on the key to determine which in-memory array to store each key in. A hash table's data will be split up into more and more independent arrays as it grows.
You can apply the same idea when storing data on multiple servers, using the output of the hash function to decide which server a record lives on. But what happens if you need to add & remove servers? If you just evenly split keys between servers, you'd need to move a lot of data when scaling.
Dynamo uses consistent hashing to tackle this tricky scaling problem. It's a way to create hash tables that can resize dynamically without having to rearrange too much existing data.
Dynamo uses a variant of consistent hashing (similar to the one used in [10, 20]): instead of mapping a node to a single point in the circle, each node gets assigned to multiple points in the ring. [...] Read and write operations involve the first N healthy nodes in the preference list, skipping over those that are down or inaccessible. pg. 210-211
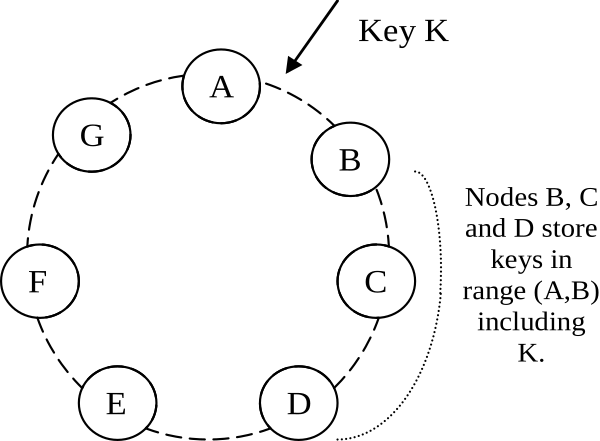
Consistent hashing imagines that servers are all evenly spaced out around a circle. Each record's primary key is then run through a hash function which outputs a degree on the circle, e.g. the key K is hashed to 10° in the diagram above. The next N servers clockwise from that key's position in the circle — B at 15°, C at 30°, and D at 45° — all store a copy of that record.
This allows engineers to add (or remove) servers with minimal data migrations. If more servers are added to the ring, the new servers "steal" tokens from existing nearby nodes in the ring. If a server leaves the system, its keys are distributed to the nearby nodes in the ring.
Some services, like Amazon's product catalog, need to be able to process more reads than writes. Dynamo allowed each application to adjust how many servers they rely on for read & write operations based on their own specific performance & consistency needs:
To maintain consistency among its replicas, Dynamo uses a consistency protocol similar to those used in quorum systems. This protocol has two key configurable values: R and W. R is the minimum number of nodes that must participate in a successful read operation. W is the minimum number of nodes that must participate in a successful write operation. Setting R and W such that R + W > N yields a quorum-like system.
In this model, the latency of a get (or put) operation is dictated by the slowest of the R (or W) replicas. For this reason, R and W are usually configured to be less than N, to provide better latency. pg. 211
In this equation, the value of N determines the durability of the object. The values of W & R impact its availability & consistency. This lives on in DynamoDB's read & write capacity units.
Conflict Resolution
Despite being visualized around a circle, the servers in the consistent hashing "rings" aren't physically right next to each other. They're placed in separate data centers to reduce the chance that a network outage would cause any particular key to become unavailable.
If one server is down, you can just read the key from the remaining servers that are still online. But what about writes? If one server that holds a key is offline & you write to the others, then you'll end up with two versions of the same record!
Unlike traditional ACID-compliant relational databases, Dynamo explicitly acknowledges inconsistencies might occur it its design:
This requires us to design applications that explicitly acknowledge the possibility of multiple versions of the same data (in order to never lose updates). Dynamo uses vector clocks in order to capture causality between different versions of the same object. pg. 210
In Dynamo, the client has to specify which version of an object it's trying to update, via the "context" it obtained from an earlier read operation. This context is stored as a vector clock, which tracks what changes led to each potential state.
That information can then be used to resolve conflicts in different ways, depending on the needs of the application. The simplest option is to use the vector clock to simply pick the most recent update. This was the conflict resolution strategy used by Amazon's session service.
Sometimes, developers might want to be more careful when resolving conflicts. Dynamo allowed these applications to resolve conflicts themselves & merge the two conflicting records based on business rules. This is how Amazon handled conflicts in their "shopping cart" service.
Hot Partition!
The use of consistent hashing to scale also explains one of DynamoDB's most notorious problems. If the key that's used to partition records around the ring isn't universally distributed (either by volume of keys or by volume of read/write requests), then too many requests will end up hitting one section of the ring:
Dynamo uses consistent hashing to partition its key space across its replicas and to ensure uniform load distribution. A uniform key distribution can help us achieve uniform load distribution assuming the access distribution of keys is not highly skewed.
In particular, Dynamo’s design assumes that even where there is a significant skew in the access distribution there are enough keys in the popular end of the distribution so that the load of handling popular keys can be spread across the nodes uniformly through partitioning. pg. 215
This problem is discussed in terms of "load imbalance". It's easier to deal with a lot of popular keys (say, during a busy weekday) than a small handful of popular keys (like a flash sale on a single item that happens at midnight).
This was an unsolved problem in Dynamo, and until recently, in DynamoDB too.
You can't have it all!
The story of Dynamo and DynamoDB is all about trade-offs. What's important to your application? What can you do without? DynamoDB won't be the right choice in many situations! In solving some of the tricky scaling problems that Amazon was facing back in 2004, Dynamo introduced a whole new set of problems that relational databases didn't have.
Nonetheless, it was at the forefront of a big shift away from "one size fits all" use of relational databases. It's a great reminder to evaluate the problems you're facing, and make sure you're using the right tool for the job!